Important Note on Usage Limits
Each model within IO Intelligence has its own value and credit consumption rate based on its complexity, capability, and computational cost.
For plan subscribers (Basic, Professional, or higher tiers), all model interactions draw from a shared usage pool. This means you can use any model available under your plan, and your total usage will count toward a single shared credit allowance — rather than having separate limits for each model.
This shared system provides maximum flexibility, allowing you to switch between models seamlessly while staying within your daily or hourly quota.
This limit is designed to ensure fair and balanced usage for all users. If you anticipate needing a higher request limit, please consider optimizing your implementation or reach out to us for assistance.
For further details on usage limits, full breakdown of rates, and how IO Credits are billed, refer to the IO Intelligence Payments page.
Introduction
You can interact with the API using HTTP requests from any programming language or by using the official Python and Node.js libraries.
To install the official Python library, run the following command:
To install the official Node.js library, run this command in your Node.js project directory:
Example: Using the IO Intelligence API with Python
Here’s an example of how you can use the openai Python library to interact with the IO Intelligence API:
This snippet demonstrates how to configure the client, send a chat completion request using the Llama-3.3-70B-Instruct model, and retrieve a response.
Authentication
API keys
IO Intelligence APIs authenticate requests using API keys. You can generate API keys from your user account:
Always treat your API key as a secret. Do not share it or expose it in client-side code (e.g., browsers or mobile apps). Instead, store it securely in an environment variable or a key management service on your backend server.
Authorization HTTP header for all API requests:
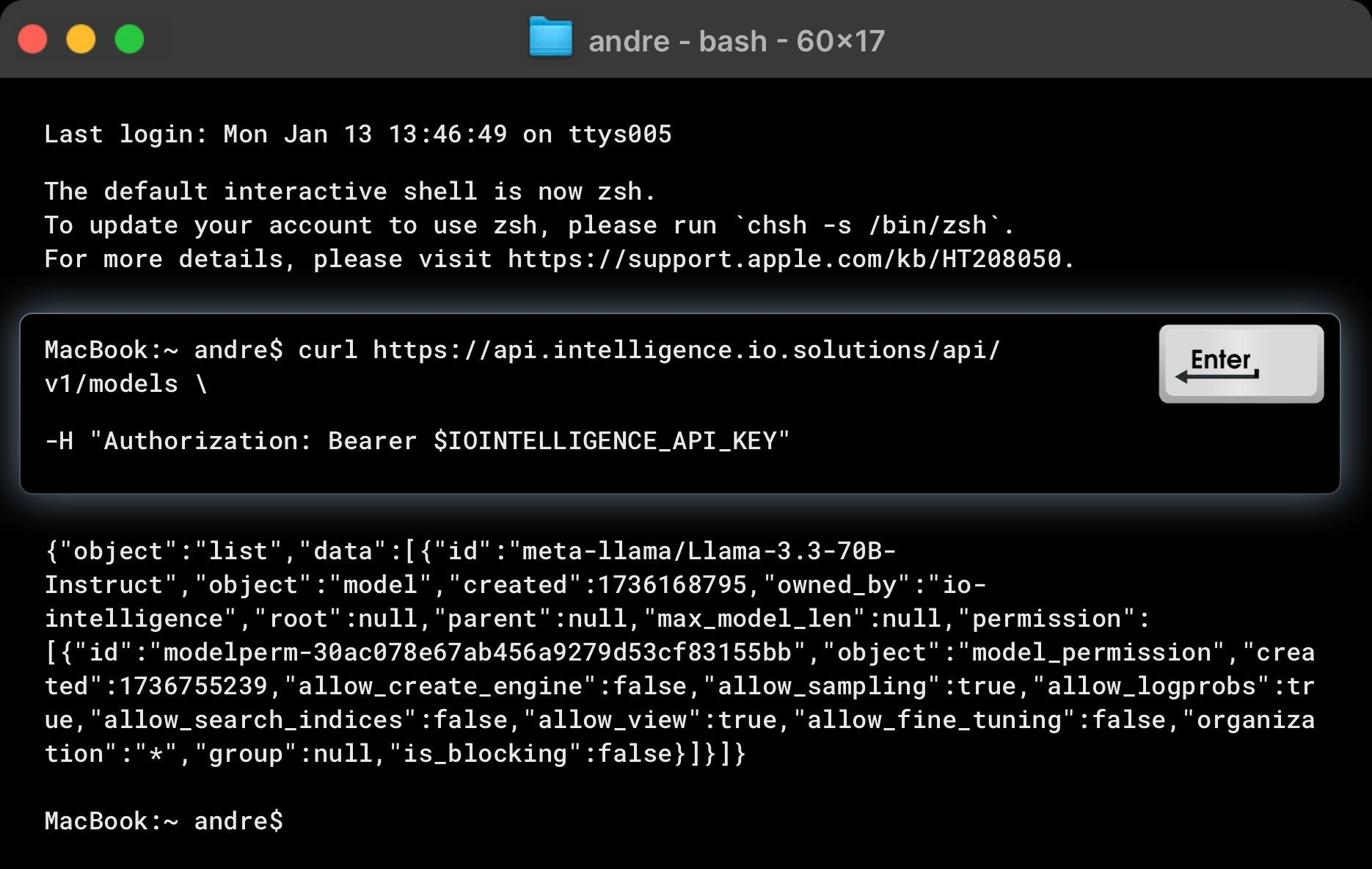
Example: List Available Models
Here’s an example curl command to list all models available in IO Intelligence:
An example response is as follows:
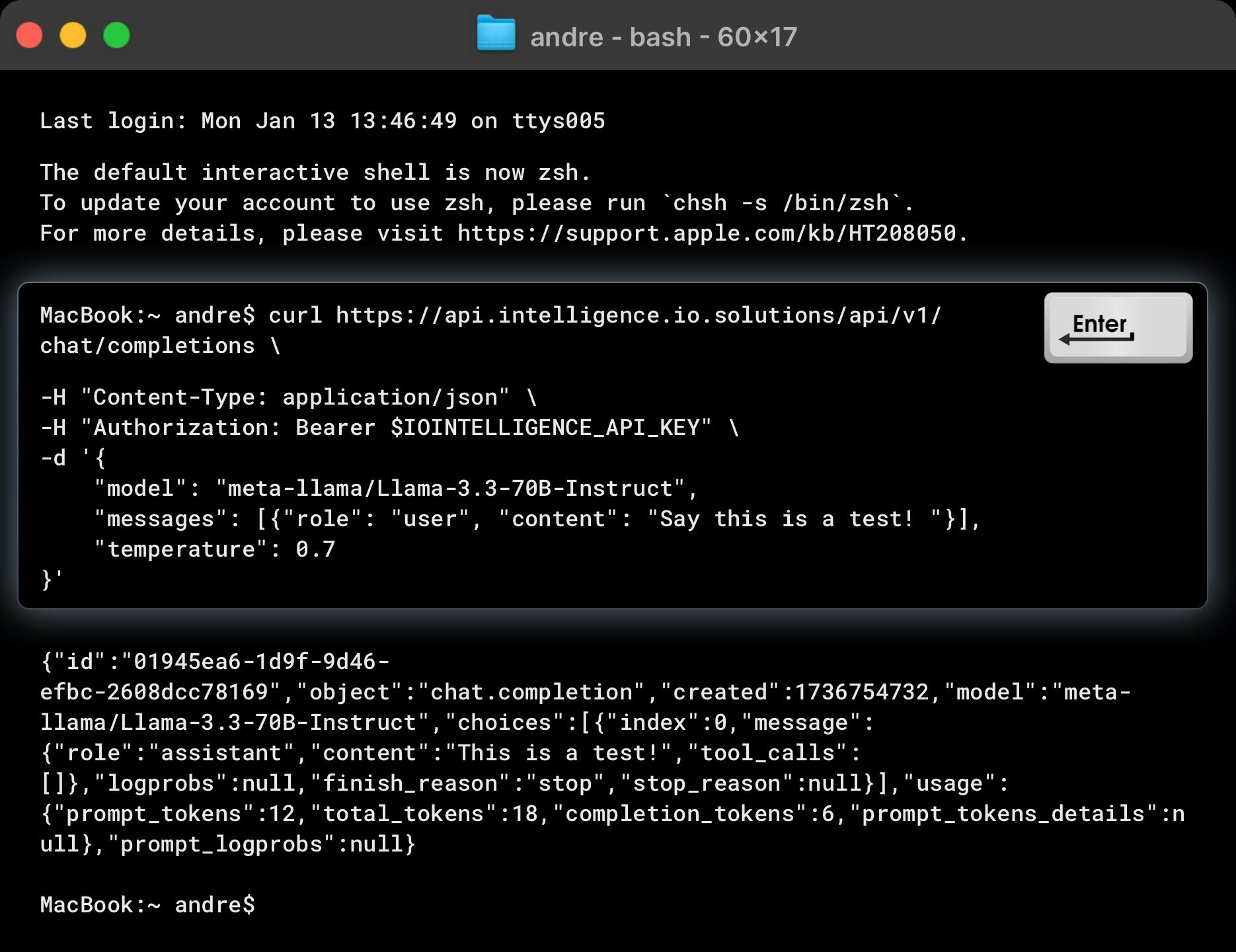
Making requests
The example below demonstrates how to make a request to the Chat Completions endpoint using curl. To test the API, replace $IOINTELLIGENCE_API_KEY with your actual API key and modify the input values as shown.
This example queries the meta-llama/Llama-3.3-70B-Instruct model to generate a chat completion for the input: “Say this is a test!”.
Example Response
The API should return a response as follows:
Key Details in the Response
- finish_reason: Indicates why the generation stopped (e.g., “stop”).
- choices: Contains the generated response(s). Adjust the n parameter to generate multiple response choices.